해싱, 해시 테이블에 대해 알아보자.
해시, 해시 테이블 ?
해시 테이블이란 키값에 매핑할 수 있는 연관 배열에 데이터를 추가하는 자료구조이다. 검색하고자 하는
Key값을 입력받아해쉬함수를 통해HashCode를 생성하고, 그 Hash코드를 배열의index로 환산하여 해당 index에값(value)을 저장합니다.
배열 arr[10]과 같이 index에 int형이 아닌 char,string 등 다른 자료형도 index로 설정 함으로써 주소에 다이렉트로 접근할 수 있습니다.
예: arr["hello"]=10
사용 분야
-
보안(Security) : 데이터의 위변조를 막기 위해 전자서명이나 블록체인, 보안 알고리즘에 사용
-
자료 구조(Data Structure) : 기억 공간에 저장된 정보를 보다 빠르게 검색하기 위해 절대주소나 상대주소가 아닌 해시 테이블(Hash Table)을 생성하는 방식
용어 정리
-
Open Hashing(개방 해싱): 주소 밖에 새로운 공간을 할당 -
Close Hashing(폐쇄 해싱): 처음에 주어진 해시 테이블의 공간 안에서 문제 해결 -
개방 주소법(Open Addressing): 충돌이 일어나면 해시 테이블 내의 새로운 주소를 탐사(Probe)하여 충돌된 데이터를 입력하는 방식(해시 함수를 통해 얻은 주소가 아닌 다른 방식으로도 주소 접근을 허용)(1) Linear Probing(선형 탐사)
해시 함수로부터 얻어낸 주소에 이미 다른 데이터가 입력되어 있음을 발견하면, 현재 주소에서 고정 폭(예를 들면 1)으로 다음 주소로 이동합니다.
특징 : Cluster(클러스터) 현상이 매우 잘 발생한다.
(2) Quadratic Probing(제곱 탐사) 선형 탐사가 다음 주소를 찾기 위해 고정폭만큼 이동하는 것에 비해 제곱 탐사는 이동폭이 제곱수로 늘어나는 것이 다르다. 특징 : 서로 다른 해시 값을 갖는 데이터에 대해서는 클러스터가 형성 되지 않도록 하는 효과가 어느 정도 있지만, 같은 해시 값을 갖는 데이터에 대해서는 2차 클러스터 발생
(3) Double Hashing(이중 해싱) 클러스터 방지를 위해, 2개의 해시 함수를 준비해서 하나는 최초의 주소를 얻을 때 또 다른 하나는 충돌이 일어났을 때 탐사 이동폭을 얻기 위해 사용(4) Rehashing(재해싱)
해시 테이블의 크기를 늘리고, 늘어난 해시 테이블의 크기에 맞추어 테이블 내의 모든 데이터를 다시 해싱하는 것 -
폐쇄 주소법(Close Addressing): 해시 함수에 의해 얻어진 주소만을 이용(다른 주소 접근X)
(1) 체이닝(Chaining)
1 연결리스트
2 이진 트리 -
해싱 함수(Hashing Function): 해당 키값을 적절한 주소로 매핑하기 위한 함수(1) 제산법
제산(Division)법은 레코드 키(K)를 해시표(Hash Table)의 크기보다 큰 수 중에서 가장 작은 소수(Prime, Q)로 나눈 나머지를 홈 주소로 삼는 방식, 즉 h(K) = K mod Q 이다.(2) 제곱법
제곱(Mid-Square)법은 레코드 키 값(K)을 제곱한 후 그 중간 부분의 값을 홈 주소로 삼는 방식이다.(3)폴딩법
폴딩(Folding)법은 레코드 키 값(K)을 여러 부분으로 나눈 후 각 부분의 값을 더하거나 XOR(배타적 논리합)한 값을 홈 주소로 삼는 방식이다.
-Shift Folding : 각 부분의 값들을 왼쪽 또는 오른쪽 끝자리에 맞추어서 계산
-Fold Boundary : 경계 지점을 접었을 때 마주치는 자리 그대로 계산(4)기수(Radix) 변환법
기수(Radix) 변환법은 키 숫자의 진수를 다른 진수로 변환시켜 주소 크기를 초과한 높은 자릿수는 절단하고, 이를 다시 주소 범위에 맞게 조정하는 방법이다.(5)대수적 코딩법
대수적 코딩(Algebraic Coding)법은 키 값을 이루고 있는 각 자리의 비트 수를 한 다항식의 계수로 간주하고, 이 다항식을 해시표의 크기에 의해 정의된 다항식으로 나누어 얻은 나머지 다항식의 계수를 홈 주소로 삼는 방식이다.(6)계수 분석법(숫자 분석법)
계수 분석법은 키 값을 이루는 숫자의 분포를 분석하여 비교적 고른 자리를 필요한 만큼 택해서 홈 주소로 삼는 방식이다.(7)무작위법
무작위(Random)법은 난수(Random Number)를 발생시켜 나온 값을 홈 주소로 삼는 방식이다.
버킷(Bucket) = key에 해당하는 value들의 묶음(해당 슬롯의 묶음)
슬롯(Slot) = key에 해당하는 value의 값(연결리스트로 연결된 값 하나 하나를 의미)
레코드(Record) = 해싱된 주소(물리적인 주소)
해시 값(Hash Value) = hash code + 인덱싱 결과 값
홈 주소(Home Address) = 해당 키값을 해시 함수에 넣어 반환된 주소
해시 충돌(Collision) = 서로 다른 키값이 해시 함수에서 동일한 값을 받아 충돌함
동의어(Synonym) = 해시 충돌이 일어난 레코드들의 집합
오버플로우(Overflow) = 더이상의 데이터를 저장할 슬롯(공간)이 없는 상태
해시 과정
Key->해시 함수에 Key넣음->Hashcode 생성->적절한 인덱스 생성->해당 인덱스주소에 저장
->데이터가 이미 존재하면 = 연결리스트로 연결
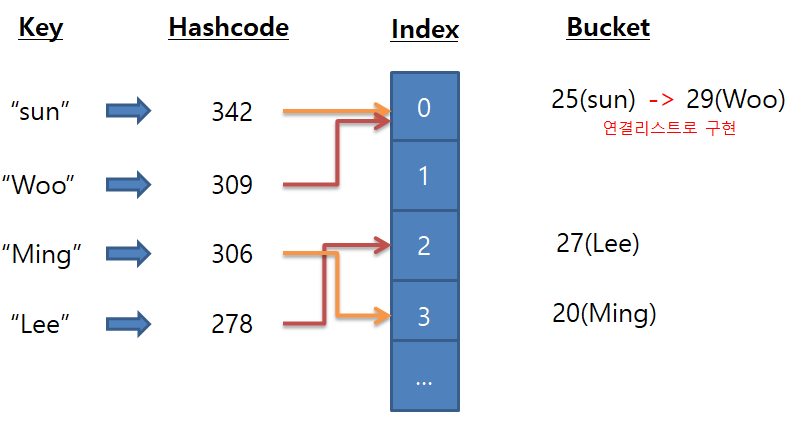
해시
-
Hash 알고리즘= 배열방을 효율적으로 사용하기위한 Hash코드 생성 알고리즘. -
해시 충돌(Collison)= 해시코드를 적절히 인덱싱한 주소가 이미 존재할 경우 -
해시 충돌시 대처방법- 추가될때마다 연결리스트를 통해 구현.
O(1)에서 최악의 경우 O(N) - 이진 트리 탐색을 통해 연결리스트보다 빠른 탐색이 가능.
O(logN) - 개방 주소법(Open Addressing)을 통해 해시 테이블 공간 안에서 다른 주소를 Probing(탐사).
Linear probing, Quadratic probing, Double Hashing, Rehashing
- 추가될때마다 연결리스트를 통해 구현.
해시 함수 예시
- 간단하게 아스키코드값을 가지고 hash함수를 구현
int getHashCode( sun )
{
//sun이라는 key값을 받아 아스키코드값을 더함.
s(115) + u(117) + n(110) = 342
//생성된 해쉬코드를 문자길이로 index 환산
342 % 3 = 0;
return 0; //index 0번을 리턴
}
Hash와 Map의 차이점
- Hash
- 자료 탐색에 Hashing을 이용한다.
- Key와 Value로 빠른 탐색속도를 보장한다. ( 시간복잡도 O(1) )
- 내부 데이터를 자동으로 정렬하지 않는다.
- Map
- 자료 탐색에 이진 탐색 트리를 사용한다. (Red-Black Tree)
- Key와 Value로 Hash보다 조금 느리다. ( 시간복잡도 O(logn) )
- 내부 데이터를 자동으로 정렬.